Der nächste Schritt in der Produktkonfiguration
3D-Konfiguratoren sind seit Jahren das Herzstück vieler CPQ-Lösungen (Configure-Price-Quote). Ob im Maschinenbau, in der Industrie oder im Retail: sie helfen, hochkomplexe Produkte und Anlagen visuell zusammenzustellen.
Doch jetzt verändert künstliche Intelligenz (KI) die Spielregeln.
Statt starrer Regelwerke eröffnen generative Modelle völlig neue Möglichkeiten – sie verstehen Nutzeranfragen, schlagen passende Konfigurationen vor oder erstellen ganze Anlagen autonom.
Ein Kunde aus der Industrie beauftragte mich, genau das zu evaluieren:
Wie kann KI sinnvoll in einen bestehenden 3D-Konfigurator integriert werden – und wie weit darf man gehen, bevor der Aufwand explodiert?
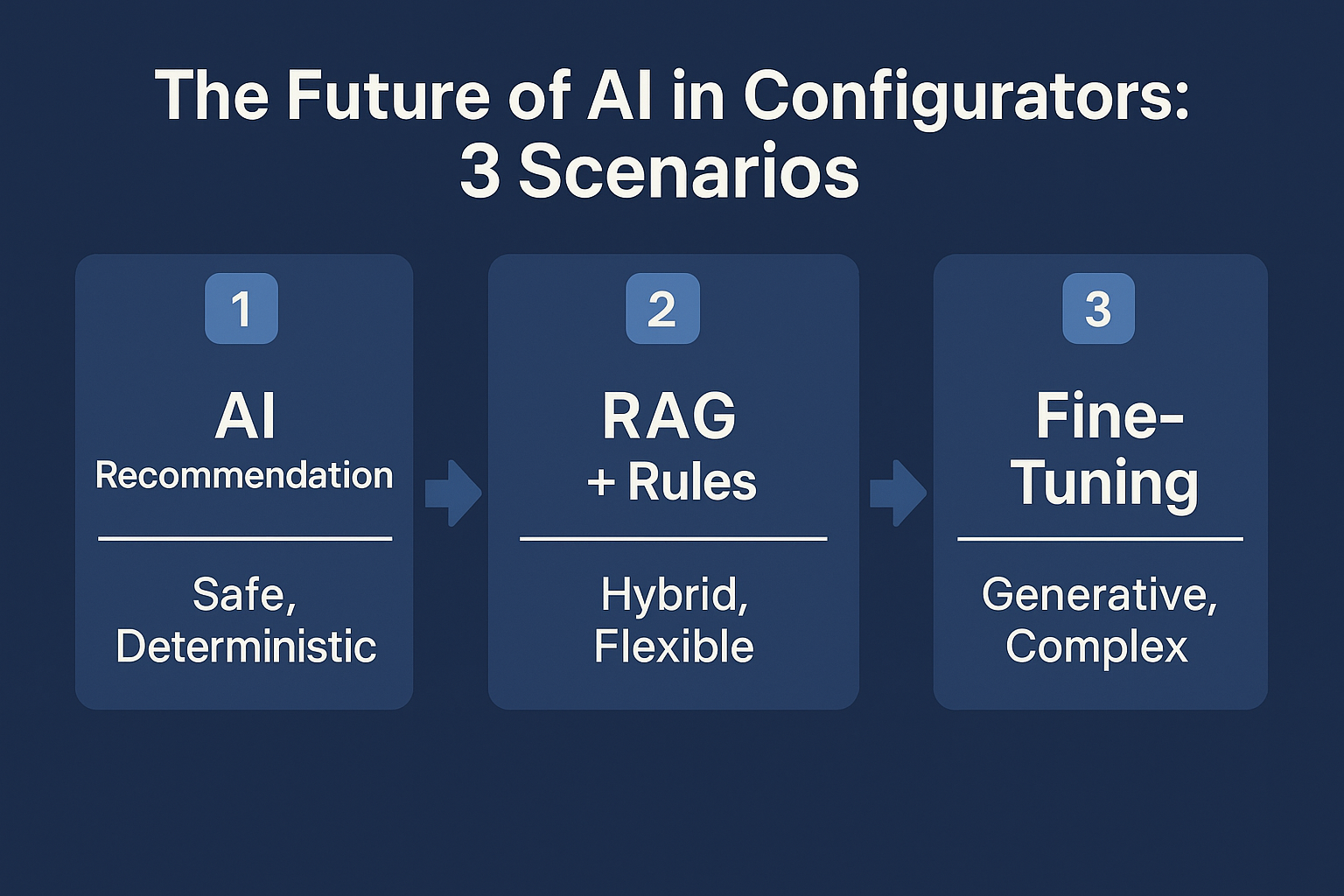
Ergebnis: Drei getestete Szenarien, von „KI als Empfehlungssystem“ bis zu „vollständig KI-generierten Konfigurationen“.
Szenario 1 – KI als Empfehlungssystem: Smart, sicher, aber limitiert
Im ersten Szenario wurde die KI als intelligentes Vorschlagssystem eingesetzt.
Der Ablauf war einfach, aber effektiv:
- Analyse der Nutzeranfrage – Die KI zerlegt den Text (z. B. „Ich brauche eine Verpackungsmaschine für Kartons mit 40 x 60 cm“) in messbare Kriterien.
- Normierung der Daten – Maße, Leistungsdaten und Optionen werden in ein einheitliches Format gebracht.
- Abgleich mit Konfigurationsdatenbank – Aus bestehenden Datensätzen werden die Top 3 passenden Konfigurationen ermittelt.
- KI-Ranking und Auswahl – Ein System-Prompt bewertet die Vorschläge und wählt die beste Option.
- Patch-Phase – Falls nötig, passt die KI die gewählte Konfiguration leicht an die Anfrage an.
Ergebnis:
Ein robustes, deterministisches System, das nie „halluziniert“. Die KI schlägt nur valide Konfigurationen vor – ideal für PoCs oder erste KI-Pilotprojekte.
Vorteile:
- Zuverlässig und nachvollziehbar
- Schnelle Implementierung
- Kein Fine-Tuning oder Training nötig
Nachteile:
- Keine neuen Konfigurationen
- Eingeschränkte Flexibilität bei neuen Anforderungen
Fazit: Ideal als sicherer Einstieg in die KI-gestützte Konfiguration.
Szenario 2 – Hybridmodell mit RAG + Regelwerk: KI wird zum Co-Ingenieur
Das zweite Szenario war deutlich ambitionierter:
Ein Hybrid-System aus RAG (Retrieval-Augmented Generation), festen Regeln und logischer Validierung.
Hier interagiert die KI nicht nur, sie denkt mit – und baut aktiv neue Konfigurationen auf.
Architektur und Ablauf:
- Dialogfähigkeit:
Wenn der Nutzer unklare Angaben macht, fragt die KI gezielt nach („Welche Raumhöhe hat Ihr Laden?“). - Embedding und RAG-Abfrage (Pinecone):
Die Anfrage wird vektorisiert und an eine RAG-Datenbank gesendet, die alle Komponenten kennt. - Komponenten-Auswahl:
Die Datenbank liefert passende Module, Bauteile oder Regale zurück. - KI-Assembler:
Eine zweite KI baut die Komponenten anhand eines vordefinierten Schemas (JSON-Struktur) zu einer vollständigen Konfiguration zusammen. - Validator + Regelengine:
Ein Validator prüft das Ergebnis und korrigiert es automatisch nach festen Regeln – z. B. Kollisionen, Abstände, X/Y/Z-Koordinaten. - Letzte Kontrolle:
Eine finale KI validiert die Logik und fragt beim Nutzer nach, wenn noch Unklarheiten bestehen.
Ergebnis:
Ein intelligentes, teil-autonomes System – deterministisch, aber in der Lage, völlig neue Konfigurationen zu generieren.
Vorteile:
- KI erstellt eigenständige, konsistente Konfigurationen
- System bleibt kontrollierbar
- Erweiterbar durch neue Regeln und Module
Nachteile:
- Hoher Entwicklungs- und Wartungsaufwand
- Jede Branche / Kunde braucht eigene Regeln
- Bei großen Szenarien (z. B. Supermärkte) wird es teuer
Fazit: Perfekter Mittelweg – KI und klassische Logik ergänzen sich. Ideal für mittlere Komplexität und Unternehmen mit klarer Regelbasis.
Szenario 3 – Vollständiges Fine-Tuning: KI schreibt die Konfiguration selbst
Das dritte Szenario war das ehrgeizigste: Ein Fine-Tuning eines Large Language Models, das komplette JSON-Konfigurationen generiert.
Ziel: die KI soll auf Basis realer Kundendaten selbstständig valide Konfigurationen erstellen, ohne externe Regeln.
Vorgehensweise:
- Datenaufbereitung:
Alle bestehenden Konfigurationen wurden in JSONL-Format überführt – inklusive semantischer Anmerkungen und Beispielbilder, um die Struktur und Bedeutung zu lernen. - Training (Fine-Tuning):
- Parallel auf OpenAI (ChatGPT 4.1) und Fireworks AI mit Llama (5 GB)
- Kosten: ca. 0,50 € pro Trainingseinheit
- Server: 80 GB RAM, 2 Epochen
- Evaluation:
Ein Evaluations-Script prüfte, ob das Modell nach dem Training gültige, konsistente JSON-Ausgaben erzeugt. - Ergebnisse:
- ChatGPT 4.1 (fine-getuned): 100 % gültige JSON-Struktur, sehr präzise.
- Llama (5 GB): 80–90 % korrekte Struktur – akzeptabel, aber fehleranfälliger.
- Limitierungen:
- Kontextfenster: 64 000–128 000 Tokens → nur Konfigurationen bis ~100 KB trainierbar.
- DSGVO: Nutzung von Cloud-basierter KI (OpenAI) ist für viele Unternehmen nicht zulässig.
- Kosten: Produktives Training kann bis zu 100 000 € verschlingen.
Ergebnis:
ChatGPT lieferte erstaunlich gute Resultate. Schon mit einem kleinen Datensatz erzeugte das Modell vollständige, valide Konfigurationen – ideal für Proof-of-Concepts.
Für produktive Systeme sind Open-Source-Modelle jedoch meist wirtschaftlicher und datenschutzfreundlicher.
Vorteile:
- Vollständige Autonomie
- Sehr hohe Lernfähigkeit
- Schnell zum PoC
Nachteile:
- Hohe Kosten
- DSGVO-Risiko bei Cloud-Anbietern
- Komplexes Retraining bei Schema-Änderungen
Fazit: Die Zukunft. Aber teuer, komplex und (noch) nicht DSGVO-konform für alle.
Vergleich der drei Ansätze
| Kriterium | Vorschlag (S1) | Hybrid RAG+Regeln (S2) | Fine-Tuning (S3) |
|---|---|---|---|
| Neue Konfigurationen | ❌ | ✅ | ✅ |
| Determinismus | ✅ | ✅ | ⚠️ Teilweise |
| Kosten | 💶 Niedrig | 💶💶 Mittel | 💶💶💶 Hoch |
| DSGVO-Konformität | ✅ | ✅ | ⚠️ Teilweise |
| Wartungsaufwand | Gering | Hoch | Sehr hoch |
| PoC-Geschwindigkeit | Schnell | Mittel | Mittel |
| Skalierbarkeit | Begrenzt | Mittel | Hoch (wenn budgetiert) |
Technische Learnings aus der Praxis
- Konfigurationen modularisieren:
Große JSON-Strukturen in kleinere Subsysteme zerlegen (z. B. Module pro Produktgruppe). - Validatoren sind Pflicht:
Ohne eine Validierungsschicht (Geometrie, Kompatibilität, X/Y/Z) ist jede KI-Konfiguration riskant. - Fehlerbudget einplanen:
Fine-Tuning ist teuer – und Retraining noch teurer. Plane von Anfang an 20–30 % Nachbesserungskosten ein. - RAG-Index sauber halten:
Pinecone oder pgvector nur mit validierten, konsistenten Datensätzen füttern. - DSGVO immer mitdenken:
Cloud-basierte Trainings (z. B. bei OpenAI) können problematisch sein – lokale LLMs (z. B. Mistral, Llama 3) sind sicherer. - Proof-of-Concept zuerst:
Nicht gleich das ganze System bauen. Ein schlanker PoC auf Szenario 1 oder 2 kann in wenigen Wochen laufen.
Fazit – KI-Konfiguratoren sind keine Zukunft mehr, sie passieren jetzt
KI verändert die Art, wie Produkte konfiguriert werden – nicht in 10 Jahren, sondern jetzt.
Ob Maschinen, Anlagen, Regalsysteme oder Retail-Layouts – wer KI-basierte Konfiguratoren nutzt, kann:
- schneller reagieren,
- komplexe Regeln automatisieren,
- personalisierte Konfigurationen anbieten
- und massiv Kosten sparen.
Wenn du selbst überlegst, KI in deine Konfiguratoren oder CPQ-Systeme zu integrieren, sprich mich gerne an. Ich helfe bei der technischen Architektur, Datenstrategie und Proof-of-Concepts – egal ob du mit ChatGPT, Pinecone, Llama oder lokalen LLMs arbeiten willst.
Schreibe einen Kommentar