Ziel: Zeigen, wie man komplexe Konfigurationen pragmatisch mit einem lokalen LLM (Qwen), n8n und JSON in SQL löst – GDPR-freundlich, reproduzierbar und ohne RAG-Overhead.
Use Case: Türen-Konfigurator
Warum dieser Ansatz?
- Schnell produktiv: Keine Vektordatenbank, kein Retrieval-Layer. Daten bleiben in SQL.
- Datenschutzfreundlich: Lokales Qwen-Modell – keine Cloud-Übertragung von Kundendaten.
- Steuerbar & deterministisch: Wo es zählt (Merging/Ranking) setzen wir Code-Logik ein. Das macht Ergebnisse nachvollziehbar.
- n8n als Klebstoff: AI-Agenten in n8n binden Tools und Datenbanken ein und orchestrieren die Schritte.
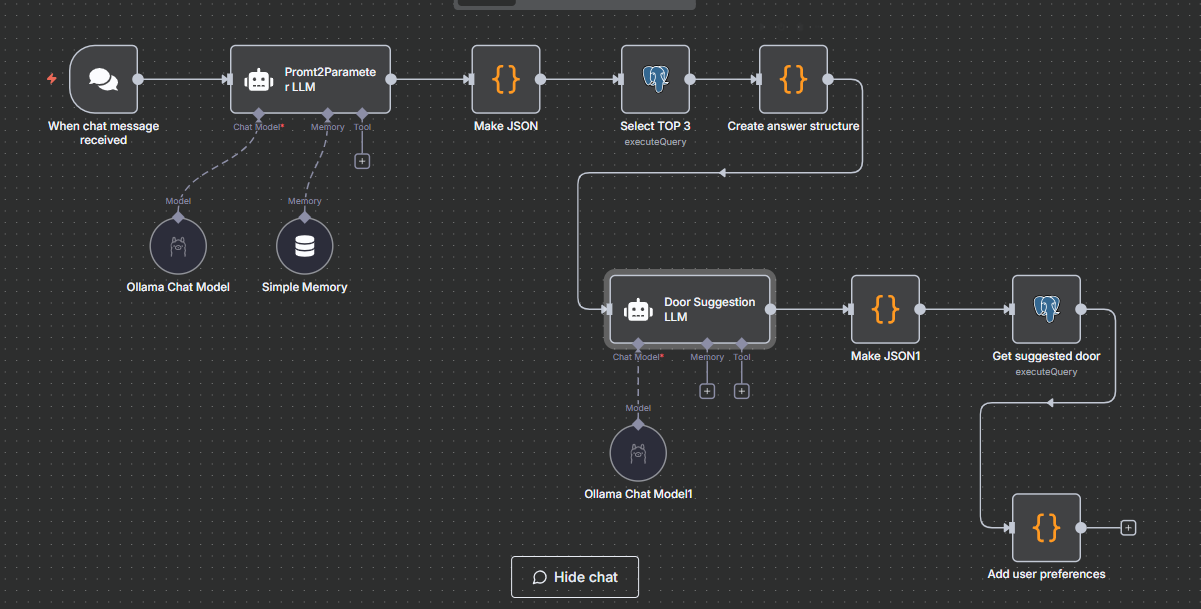
Architektur auf einen Blick
- User → n8n (Text-Prompt)
- AI-Agent #1 (Qwen, lokal): Intent & Parameter aus User-Text extrahieren
- Code-Validierung: JSON normalisieren/prüfen
- SQL-Abfrage: Top-3 nahe Kandidaten holen
- Deterministisches Merging: Kandidaten mit Nutzerwunsch abgleichen, Score berechnen
- AI-Agent #2 (Qwen, lokal): Erklärung + finale Empfehlung formulieren
- Finale Konfiguration: SQL-Datensatz der gewählten Tür laden, Nutzer-Wünsche einblenden, zurückgeben
Schritt-für-Schritt: So haben wir den KI-Konfigurator gebaut
1) Nutzerwunsch parsen (AI-Agent #1)
- Node: AI Agent in n8n mit lokal laufendem Qwen-Instruct.
- Prompt-Ziel: Extrahiere strukturierte Felder (z. B.
breite_mm,höhe_mm,farbe,schloss_typ,budget,lieferzeit_prio). - Output-Beispiel:
{
„breite_mm“: 900,
„höhe_mm“: 2100,
„farbe“: „anthrazit“,
„schloss_typ“: „dreipunkt“,
„budget“: 1200,
„lieferzeit_prio“: „hoch“
}
2) JSON validieren & normalisieren (Code)
Beispiel im n8n Code-Node:
2) JSON validieren & normalisieren (Code)
Beispiel im n8n Code-Node:
// Roh-Output vom AI Agent (z.B. in $json.output als String)
let raw = ($json.output ?? “).trim();// Entferne evtl. Codefences (
json ...)
raw = raw
.replace(/^(?:json)?\s*/i, '') .replace(/$/i, “)
.trim();let parsed;
try {
parsed = JSON.parse(raw);
} catch (e) {
throw new Error(‚AI-Agent hat kein gültiges JSON geliefert: ‚ + e.message + ‚ | raw=‘ + raw);
}// Gib alles so zurück, wie es ist
return [{ json: parsed }];
3) Top-3 Kandidaten aus SQL holen
Tabellenidee: doors(id, specs jsonb, stats jsonb, tags text[], ...)
SQL-Beispiel:
SELECT * FROM doors
WHERE breite_mm BETWEEN $1-150 AND $1+150
AND hoehe_mm BETWEEN $2-150 AND $2+150
AND lagerbestand > 0
— AND lower(farbe) = lower($3)
LIMIT 3;
4) Deterministisches Merging & Scoring (Code)
Beispiel-Scoring:
// nimmt alle Items vom PG-Node
const req = {
prompt: $(‚When chat message received‘).first().json.chatInput // optional: Originalprompt
};function line(c) {
// kompakt, deterministisch, eine Zeile pro Tür
return[${c.id}] ${c.name||''} | ${c.breite_mm}x${c.hoehe_mm}x${c.dicke_mm} | Farbe:${c.farbe} | B:${c.brandschutz} | RC:${c.sicherheitsklasse} | Glas:${c.glasanteil_prozent}% | Drueckergarnitur:${c.druekergarnitur} | Oeffnungsart:${c.oeffnungsart} | Anschlag:${c.anschlag} | Oberflaeche:${c.oberflaeche} | Matierial:${c.material} | dB:${c.schallschutz_db} | €:${c.preis_eur} | LZ:${c.lieferzeit_wochen};
}const candidates = items.map(i => i.json);
return [{
json: {
request: req,
lines: candidates.map(line),
ids: candidates.map(c => c.id)
}
}];
So entsteht eine Rangliste mit klarer Logik.
5) Begründete Empfehlung formulieren (AI-Agent #2)
- Input: Nutzerwunsch + Top-3 Kandidaten + Scores/Abweichungen
- Aufgabe: „Wähle genau 1 Kandidat. Erkläre in 3–5 Sätzen, warum er am besten passt. Weisen auf die wichtigsten Kompromisse hin.“
- Ergebnis: Eine klare, menschlich lesbare Empfehlung.
Beispiel von dem Systempromt:
Du bist Tür-Expert. Du wählst aus Kandidaten (Türen) die beste Variante anhand Nutzerwunsch.
Gewichtung: Maße (Abweichung minimal) > Farbe passend > restliche Merkmale.
Gib STRICT JSON wie beschrieben:
- Id der Tür, die am meisten passt. Das Feld muss immer „door_id“ heißen.
- Kurze erklärung warum du diese Tür ausgewählt hast.
- Angepasste Tür: final_json
- Basis-Konfiguration: original_json
Antworte immer ausschließlich als STRICT JSON, ohne Codefences und ohne Text. Verwende niemals undefined/NaN/Infinity; nutze null.
6) Finale Konfiguration bauen
- Tür-ID aus SQL holen
- Nutzerwünsche einblenden (Optionen ergänzen, Defaults überschreiben)
- Finales JSON zurückgeben, kombiniert mit Empfehlungstext
Warum ohne RAG?
- Einfachheit & Speed: Für strukturierte Kataloge reicht SQL + Heuristik.
- Kontrolle: Scoring definieren wir selbst.
- Kosten: Keine Vektor-Infrastruktur.
Wann RAG?
Wenn viele Regeln, lange Beschreibungen oder Textwissen im Spiel ist. Genau das zeigen wir in Teil 2 mit Möbel-Türen, RAG und Validierung.
Betrieb & Datenschutz
- Lokal heißt nicht automatisch compliant, aber es reduziert Transfers und Risiken.
- n8n-Agenten binden Tools kontrolliert ein und machen Abläufe transparent.
- Qwen als lokales Modell sorgt dafür, dass Kundendaten nicht nach außen gehen.
Praxis-Tipps
- JSON-Schema prüfen, bevor Daten in SQL landen.
- Hybrid-Schema: feste Felder als Spalten, variable Eigenschaften in
jsonb. - Explainability: Scores und Abweichungen mitloggen, damit Nutzer verstehen, warum eine Empfehlung gewählt wurde.
- Fallback: Wenn nichts passt, nächstbeste Alternative + Konfliktliste anzeigen.
- Testfälle: 20–30 realistische Szenarien reichen, um 80 % der Fehler zu finden.
Vor- & Nachteile dieses Ansatzes
Vorteile:
- GDPR-freundlich
- Einfach & schnell live
- Deterministisch und kontrollierbar
- Gut erklärbar
Nachteile:
- Grenzen ohne RAG (kein Textwissen)
- Scoring muss gepflegt werden
- Schema-Drift bei JSON-Strukturen
- Kein automatisches Lernen
Hier gleich im Video das finale Produkt sehen:
Fazit
Für strukturierte Produktkonfigurationen ist SQL + lokales Qwen + n8n ein schneller, datenschutzfreundlicher Weg. Wir kombinieren LLM-Stärken (Parsing, Erklärung) mit deterministischem Code (Scoring, Merging).
In Teil 2 der Serie zeigen wir, wie RAG & Validierungsregeln den nächsten Level eröffnen.
Du willst deine Konfigurationen digitalisieren oder mit KI beschleunigen?
Melde dich bei mir – ich helfe bei Architektur, Umsetzung und Go-Live.
Schreibe einen Kommentar